안녕하세요 테크리트입니다.최근 들어 개발자들 사이에서뿐만 아니라 일반인, 예술가들에게도 매우 핫한 이슈가 있습니다. 그림을 그리는 AI(인공지능)입니다.그림을 그려주는 AI, 작곡하는 AI, 소설을 써주는 AI 등 여러 종류의 AI가 예전에도 있었지만 이번에 나온 건 좀 특별해요. 무엇이 특별한지 그리고 사용법을 이번 포스팅에서 함께 살펴보겠습니다. Stable Diffusion의 특별한 점

AI는 Artificial Intelligence의 약어입니다. 한국어로 말하면 인공 지능인데, 이 인공 지능과 일반적으로 만든 프로그램의 최대의 차이점은 무엇일까요? 학습의 가능성입니다.통상 작성하는 프로그램은 최초로 개발자가 지시한 범위 내에서만 행동할 수 있습니다.”사용자가 x와 입력하면 y결과를 출력하는 “과 프로그래머가 입력하면 프로그램은 그렇게밖에 행동할 수 없습니다. 그러나 인공 지능의 경우 학습을 통해서 출력하는 결과가 다양화하고 많아질 수 있습니다.그렇다면 이”학습”을 어떻게 하게 하느냐가 중요하지만, 이런 과정을 기계 학습(Machine Learning)라고 합니다. 여기에서도 매우 다양한 종류가 있고 또 많은 수학적 지식이 필요합니다. 이 부분의 자세한 얘기는 이번 기회가 있으면 하도록 하겠습니다.아무튼 그림을 그려AI가 있다고 가정하면 이 AI는 처음에는 아무것도 그릴 수 없는 백지 상태라고 보는데, 이 AI에 여러가지 그림을 보이면서 학습시켜야 합니다. 많은 그림을 보이면 보일 정도로 학습에 도움이 됩니다.이들의 학습 작업은 보통 컴퓨터로 할 만큼 녹록하지 않습니다. 매우 많은 컴퓨터 자원이 필요합니다. 수억원 이상을 투자하고 준비한 그래픽 카드를 병렬로 구성해야만 원활하게 학습시킬 수 있습니다. 실제로 대부분의 연구 기관이 거액의 연구비를 걸어 이런 연구에 투자하고 있습니다.그런데 Stability AI라는 회사에서 막대한 자원으로 학습시킨 인공 지능 모델을 민간에게 무료로 공개했습니다. 일반적으로 이렇게 어려운 연구한 데이터 모델은 공개하지 않지만, 너무 대인 관계의 면을 보였습니다. 이어 그림을 그리고 다른 AI모델은 학습 데이터가 있어도 해당 모델을 쓰고 그림을 실제로 그리기 위해서는 그림을 그리는 쪽에서도 그래픽 카드의 자원을 매우 많이 써야 합니다.그러나 Stability AI에서 공개한 인공 지능 모델, Stable Diffusion의 경우는 일반인이 사용하는 그래픽 카드 수준이라도 제대로 그림을 그릴 수 있을 만큼 자원을 덜 사용하기 때문에 이번 너무 혁신적이라고 평가되고 있습니다. Stable Diffusion WebUI by AUTOMATIC1111

Stable Diffusion WebUI는 Stable Diffusion 인공지능 모델을 웹페이지 UI로 쉽게 사용할 수 있도록 제작한 오픈소스 프로젝트입니다. 깃허브의 AUTOMATIC 1111이라는 사용자가 주축이 되어 많은 사용자들의 공헌으로 만들어졌으며 현재도 계속 업데이트 되고 있습니다.
인기글




원래는 cmd창에서 명령어를 입력해서 그림을 그려야 하는데 웹UI를 사용하면 웹페이지에 이렇게 키워드와 옵션값을 입력해서 쉽게 이미지를 생성할 수 있습니다.상단 프롬프트에는 이미지를 만들고 싶은 주요 키워드를, 그 아래 Negative prompt에는 이미지에 들어가지 않았으면 하는 키워드를 넣으면 됩니다. 그 외의 요소는 아래에서 다시 설명하겠습니다.

숲, 사실적, 날카로운 초점, 필드 깊이, 5개의 큰 나무, 꽃
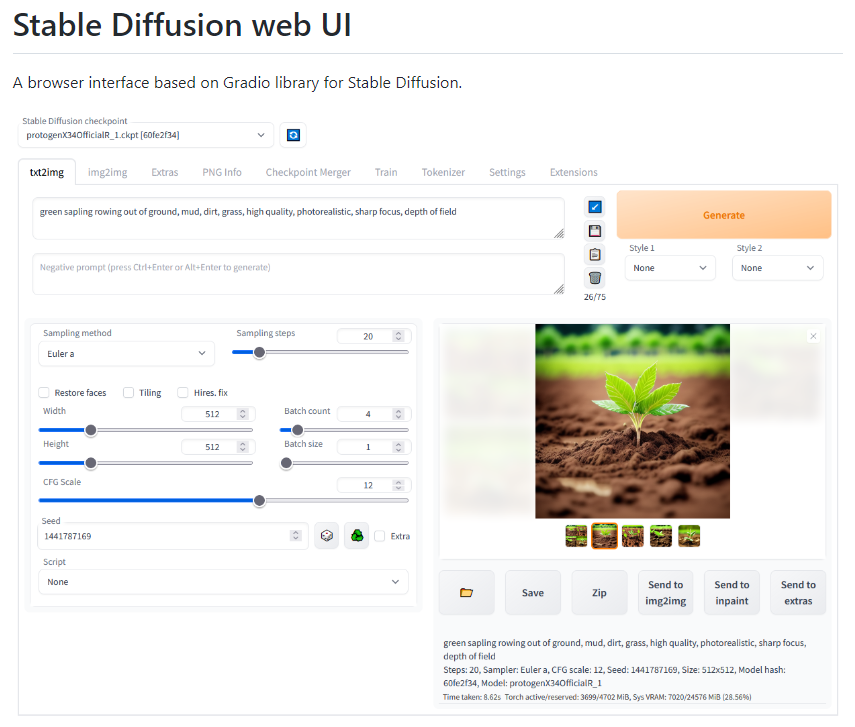
나는 테스트 겸 위의 프롬프트를 넣어 이미지를 작성해 보았습니다.

Generate 버튼을 누르면 이렇게 프로그레스 바가 올라가서 남은 시간도 보여줍니다.

잠시 후 이렇게 사진이 작성되었습니다. 어떤 사진인지 자세히 살펴볼까요?
큰나무5그루라고했는데저는다섯그루가다앞에있는것을생각해서그리라고했는데두그루는계속뒤에있는것으로그려있네요. 프롬프트를 상세하게 입력할수록 자신이 원하는 이미지에 맞게 그려집니다.

웨딩드레스를 입은 귀여운 소녀가 소녀의 길을 걷고 있다, 미소, 행복, 꽃 샤워, 긴 노란 머리, 파란 눈
이번에는 버진 로드를 걸어가는 웨딩드레스를 입은 신부를 그려달라고 하겠습니다. 머리색은 노란색이고 눈색은 파란색으로 썼어요.
이번에는 버진 로드를 걸어가는 웨딩드레스를 입은 신부를 그려달라고 하겠습니다. 머리색은 노란색이고 눈색은 파란색으로 썼어요.

4개를 작성해봤습니다.다른 건 다 좋은데 뭐 하나가 이상해요. 버진 로드라고 쓰여 있었기 때문에, 저는 웨딩 홀의 그 버진 로드를 예상하고 있었습니다만, 이상하게도 도로 위를 걷고 있는 것 같습니다.내가 아는 버진로드의 의미가 그렇지 않을까 해서 인터넷으로 찾아봤어요.

네이버에 검색해보니 버진로드는 일본에서 유래한 말이지 정통 영어 단어가 아니라고 합니다.영어문화권에서는 Walking down the aisle이라는 말을 쓴대요.그럼 다른 키워드로 이미지를 만들어보겠습니다.웨딩드레스를 입은 귀여운 소녀가 통로를 걷고 있다, 미소, 행복, 꽃 샤워, 긴 노란 머리, 파란 눈웨딩드레스를 입은 귀여운 소녀가 통로를 걷고 있다, 미소, 행복, 꽃 샤워, 긴 노란 머리, 파란 눈이제 인공지능이 제 의도를 파악한 것 같군요.이처럼 사람 외에도 Stable Diffusion은 사물, 풍경, 동물, 곤충 등 다양한 피사체를 아주 사실적으로 그려내고 또 애니메이션풍으로도 그려내며 특정 작가풍으로도 그려낼 것으로 보입니다. 예를 들어 위의 키워드를 그대로 두고 “Anime” 이라는 키워드만 추가로이렇게 애니메이션에서 나오는 것 같은 도안으로 그려줘요.제가 일주일 남짓 이 프로그램을 사용해봤는데 성능이 정말 상당합니다. 이제 일반인들도 대부분의 만화는 그릴 수 있을 정도로 인공지능이 발전했다고 볼 수 있을 것 같아요.아직 일부 부족한 점이 보이기는 하지만 조금 더 발전하면 정말 완벽한 그림을 그릴 수 있지 않을까 싶네요. Stable Diffusion WebUI 설치 방법Stable Diffusion WebUI는 Github 오픈소스 프로젝트 웹페이지에서 설치 방법을 확인할 수 있습니다.구글에서 AUTOMATIC1111/stable-diffusion-webui를 검색합니다.그러면 맨 위에 깃허브 링크가 표시됩니다. 이것을 클릭해서 접속해 줍니다.아래 Installation and Running 부분을 확인하세요. Python 3.10.6(또는 현재 기준으로 최신 버전)을 설치합니다. 설치 과정에서 PATH 환경 변수에 Python을 추가한다는 체크박스가 있는데, 이를 꼭 선택해주세요. – 구글에서 Python을 검색해서 쉽게 설치할 수 있습니다.2. git을 인스톨 합니다.git 웹사이트에서 Windows용 인스톨 파일로서 인스톨 해 주세요.3.cmd를 열고 설치하려는 폴더에 cd 명령을 입력하고 이동한 후 아래 명령으로 stable diffusion webui 저장소를 다운로드합니다.git クローン https://github.com/AUTOMATIC1111/stable-diffusion-webui.git4. ckpt모델 파일을 다운로드하고 models폴더에 저장합니다. 이 파일은 gitHub설치 설명 페이지의 dependencies링크를 더듬어 보면 다운로드 방법이 설명되어 있습니다.5. 마찬가지로 dependencies링크에서 GFPGANv1.4.pth파일의 다운로드 방법을 확인하고 다운로드하고 프로그램의 루트 디렉토리(webui). py파일이 있는 곳)에 저장합니다.6. webui-user.bat파일을 실행하고 프로그램을 시작합니다.7. 프로그램을 시작한 뒤에는 cmd창에 표시된 주소를 브라우저에 입력하고 접속합니다. Stable Diffusion WebUI사용 방법며칠 전 localization 관련 커밋이 게재됨에 따라 한글화도 곧 이뤄질 것으로 보입니다. 하지만 아직 영어 버전이기 때문에 영어 버전을 기준으로 간단한 사용법을 설명하겠습니다.위의 페이지에서 txt2img탭에 대해서만 설명합니다. 다른 모드에 대해서는 다음에 기회가 있으면 설명합니다.txt2img의 바로 아래 프롬프트 입력 란:화상을 작성할 때 포함하고자 하는 키워드, 그 아래 프롬프트 입력 란:화상을 작성할 때 포함하고 싶지 않는 키워드 SamplingSteps:샘플링 회수, 기본적으로 최대 150회까지 설정할 수 있는 샘플링을 많이 하는 만큼 품질이 좋아진다고 생각하세요.Sampling method:샘플링 방식을 선택하는데 각 메서드에 의해서 결과물이 크게 다릅니다. 일부 방법으로 샘플링 회수가 지나치게 커지면 오히려 결과가 이상하기도 합니다.Width, Height:이미지의 폭과 높이. 너무 크면 그래픽 카드가 감당할 수 없게 되고 검은 화상이 출력될 가능성이 있습니다.Batch count:화상을 생성하는 횟수 Batch Size:한 작업 주변의 화상을 생성 하는 개수. 즉, Batch Size X Batch count가 총 영상의 개수입니다. Batch Size가 병렬 작업의 개수와 볼 수 있으므로 많은 이미지를 생성할 경우는 Batch Size의 분 먼저 늘리기를 추천합니다.CFGScale:프롬프트에 얼마나 충실히 따를 것인지에 대한 수치. 높을수록 프롬프트에 착실히 따라서 화상을 생성하고 낮을수록 보다 다양한 화상을 생성합니다.Seed:랜덤 한 화상을 작성하는 데 사용하는 베이스 변수. 난 종으로 생각하면 좋은데-1에 두면 랜덤으로 생성하고 사용합니다. Seed을 같이 하면 같은 이미지가 나올 가능성이 있습니다.Stable Diffusion WebUI에는 문자에서 영상을 작성하는 기능 이외에도 다양한 기능이 있습니다. 화상에서 화상을 만드는 기능, 화상의 일부만 바꾸는 기능 및 화상의 해상도를 높이는 기능 등이 있는데, 시간이 있으면 다른 기능에 대해서도 털어 봅시다. Stable Diffusion을 사용하여 만든 화상의 저작권은?이 부분은 상당히 민감한 문제여서 아직도 갑론을박이 이루어지고 있습니다.Stable Diffusion은 수많은 학습을 거치며 학습 데이터에 근거하여 그림을 그립니다. 그렇다면 해당 학습 참고가 된 그림의 작가가 있겠지만, 해당 작가들은 손을 쓸 방법도 없는 본인들의 “그림”을 빼앗긴다는 것입니다.예컨대 A라는 유명한 작가가 있다고 가정합니다. Stable Diffusion이 A가 그린 만화와 그림을 수천장 학습하고 A와 같은 무늬에서 만화를 그릴 수 있게 되었습니다. A보다 훨씬 빨리, 더 정교하게 그리게 됐을 때 A는 큰 피해를 입을 것입니다. 이런 때 이 그림의 저작권은 AI을 쓰고 그림을 만든 사람에게 귀속합니까?지금 예술에 종사하는 많은 사람들은 이런 AI에 대해서 반대 입장을 밝히고 있습니다. 실제로 Stable Diffusion은 학습 때”실제 사람이 그린” 수많은 그림을 학습하면서 성장하고 애니메이션 만화 등 대중 문화계 그림의 경우 해당 계열의 팬 아트가 많이 게재된 몇개 사이트의 이미지를 크롤링 하고 학습했다고 알려지고 있습니다.또 일부에서는 Stable Diffusion에서 생성한 그림을 자신이 그린 그림이라고 속이고 팔다 적발되기도 했어요. 이는 Stable Diffusion의 사용 라이센스에도 위배되지만 Stable Diffusion에서 생성한 내용물을 사용할 때는 반드시 Stable Diffusion에서 만들었다는 내용을 명시해야 합니다.AI가 발전하면서 확실히 사람들에게 도움이 될 부분이 너무 많겠지만 한편으로는 피해를 줄 수 있는 부분이 있지만, 적당한 타협점을 찾는 것이 중요하다고 생각됩니다. 이상, 테크 리트이었습니다.